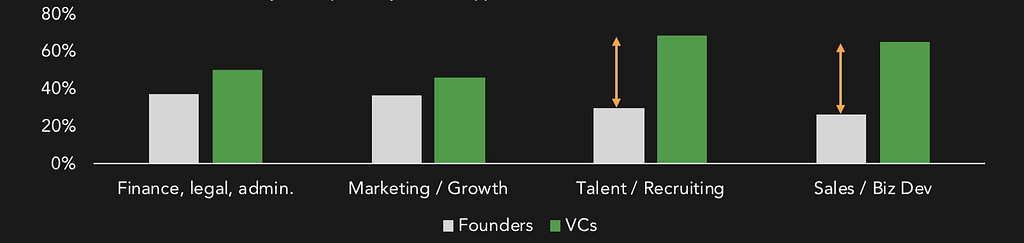
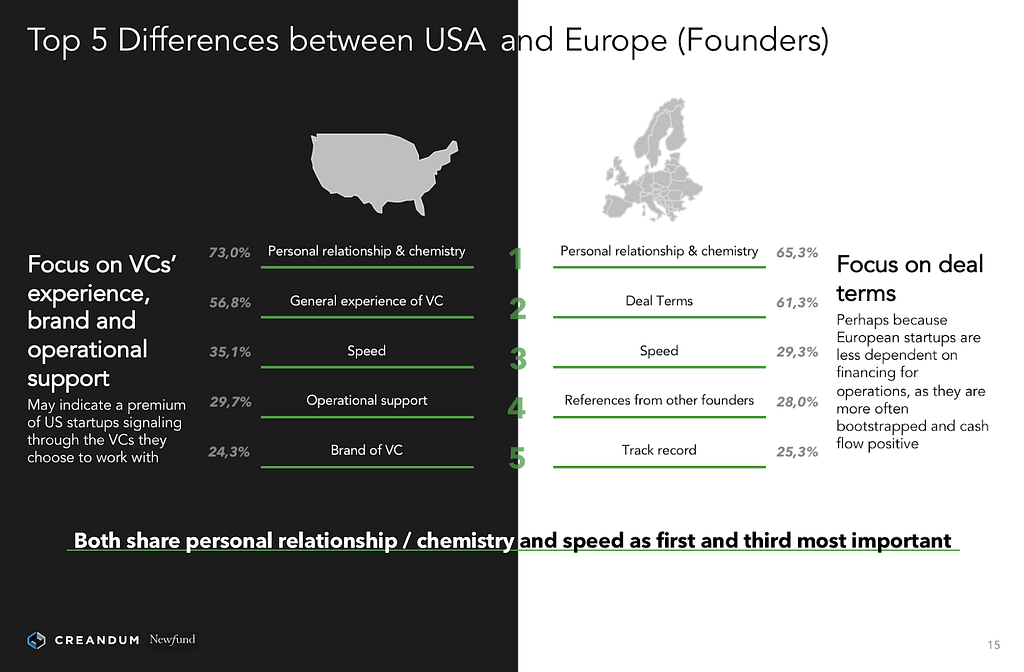
These are some of the best comments from Basic Income, Not Basic Jobs: Against Hijacking Utopia. I’m sorry I still haven’t gotten a chance to read everything that people have written about it (in particular I need to look more into Scott Sumner’s take). Sorry to anyone with good comments I left out.
Aevylmar corrects my claim that Milton Friedman supported a basic income:
Technically speaking, what Milton Friedman advocated was a negative income tax, which (he thought, and I think) would be much more efficient than basic income – I don’t remember if these are his arguments, but the arguments I know for it are that the IRS can administer it with the resources it has without you needing a new bureaucracy, it doesn’t have the same distortionary effects that lump sum payment + percentage tax does, and it’s probably easier to pass through congress, since it looks as though it costs less and doesn’t have the words ‘increasing taxes’ in it.
And Virbie further explains the differences between UBI and negative income tax:
The main difference is that discussing it in terms of NIT neatly skips over a lot of the objections that people raise to flat UBIs that are abstractly and mathematically (but not logistically or politically) trivial. Many of these focus on how to get to the new policy position from where we are now. For example, people ask both about how a flat UBI would be funded and why rich people should receive a UBI. Given that the tax load to fund a basic income plan would likely fall on the upper percentiles or deciles, a flat UBI + an increase in marginal tax rates works out to a lump sum tax cut for high-earners and a marginal tax increase. Adding negative tax brackets at the bottom of the existing system and modifying top marginal rates is a simpler way to handle this and extends gracefully from the current system instead of having to work awkwardly alongside it.
In the example above, the NIT approach has the logistical advantage of the bureaucracy and systems we already have handling it more easily. And the political advantage of the net cost of the basic income guarantee looking far smaller than for flat UBI, since we’re not including the lump sum payments to upper-income people (that are more than offset by their marginal tax increases).
There’s some further debate on the (mostly trivial) advantages of NIT or UBI over the other in the rest of the thread.
Tentor describes Germany’s experience with a basic-jobs-like program:
We had/have a similar thing to basic jobs in Germany and it worked about as well as you would expect. Companies could hire workers for 1€/hour and the state would pay social security on top of that. The idea was that long-term unemployed people would find their way back to employment this way, but companies just replaced them with new 1€-workers when their contract was over and reduced fully-paid employment because duh!
Plus people on social security can be forced to take jobs or education. As a result a lot of our homeless are depressed people who stopped responding to social security demands because that’s what caused their depression.
(Links are to German Wikipedia, maybe Google translate helps)
Another German reader adds:
I agree that it doesn’t work as expected in Germany, but I think it it important to point out that not everyone is allowed is to hire workers for 1€. The work has to be neutral to the competition and in the public interest. So people are hired at a lot of public institutions (e.g. schools, universities, cleaning up the city).
Additionally these jobs improved the unemployment statistics at a low cost for the government, as people who are working in these jobs count as employed although most of these jobs are only part time jobs.
Murphy describes the UK experience:
One likely model for “guaranteed jobs” is the disaster that they tried in the UK for a while.
Basically the government partners with crappy low-skill employers who’s owners are buddy buddy with the right ministers and the state provides them with a steady supply of slaves jobseekers.
They then declare it all “Education”, in fact pay a premium to the corporate partners for “providing education” in the form of 5 minutes showing someone who’s already worked shelf stacking jobs how to stack shelves.
The people who love the scheme tend to genuinely believe the fiction about “education” because they tend to be the kind of people who believe that all poor people are thick and can’t learn and really do need 6 weeks to learn how to put a tin of beans on a shelf.
Your manager is abusive? tough luck. You have no rights. if you quit or the supervisor just declare you not to be working hard enough you lose your dole money. Hope you like starvation and death.
So if your manager demands you suck his dick then make sure to bring kneepads to work.
Remarkably employers who suddenly had the option of free labor along with free money from the government leapt at the option so people found themselves fired from positions only to find themselves required to do the same job a few weeks later only this time without pay.
The government was taken to court over it, the court rules it unlawful.
“I don’t think I am above working in shops like Poundland. I now work part-time in a supermarket. It is just that I expect to get paid for working.”
So the UK Parliament passed retrospective legislation to overrule the courts.
Anyone and I mean anyone with a libertarian bone in their body and an ounce of principles should be disgusted by “guaranteed jobs” because it’s thinly disguised slavery and a drive to replace paid work with forced labor.
Herbert Herbertson on the Native American experience:
I’ve said it before, but beyond the Alaska permanent fund, there’s an area where we could see a TON of extremely varied UBI case studies that I’ve never really seen anyone talking about UBI mention, one where we could see the limits, the pitfalls, and the benefits of a UBI as applied to a population with extremely deep historical poverty, intergenerational trauma, and serious substance abuse issues: Native American tribes with (more or less) successful gaming operations who distribute a portion of profits to their members in the form of a “per capita” payment.
My anecdotal experience is that it’s no panacea, but that it sure as fuck helps–but there’s a lot of potential data out there to move beyond anecdote.
Unirt describes the Finnish experience:
There has been a universal employment trial in a Finnish town Paltamo, which lasted 3 or 4 years. Apparently it costed the government more than just paying unemployment subsidies, and they found that undesirable.
richarddormersvoice describes the Chinese experience:
the closest thing to a guaranteed work program today is the iron rice bowl in china, which is a clusterfuck.
https://en.wikipedia.org/wiki/Iron_rice_bowl
from what I know/heard:
a) 50% of state-owned enterprises are operating at a loss, meaning they are inefficient, corrupt, unproductive, and generally terrible places to work. it is stable though because it’s guaranteed by the ccp.
b) areas where irb has been liberalized do much better economically, shenzhen, guangdong, chongqing, while much of the northeast has barely developed.
c) even so, getting rid of the irb is difficult because, well, people, firms, politicians are dependent on it. chinese politics is heavy on corruption, soes are especially heavy on corruption.
Doktor Relling describes the Scandinavian experience:
Scandinavian countries have for some years had something functionally similar to a Universal Basic Job guarantee. We label it “activation policies”.
Since we have been doing this for some years (and increasingly the rest of Europe likewise), we have some empirical knowledge of the pros and cons. For those interested, here is a simplified walkthrough of the system (full disclosure: I spend my working life as a health & social policy researcher – and I believe that, on balance, this policy is better than the alternatives.) 1) You start out by introducing a means-tested social assistance scheme that covers everybody – including single males at subway stations shouting GRAAAGH to passers by. 2) You require that those who apply for social assistance, work for the benefit if they are able to work. 3) To find out if they are able to work, the social assistance administration does a work test.
Effects of the system: When the social assistance administration does the work test, it discovers that many long-term social assistance claimants are actually disabled (which was never found out before we introduced the activation requirement plus work test). Hence they qualify for a disability pension instead (somewhat similar to US Special Supplementary Income). In short: This version of a UBJ channels the unemployable GRAAGHs among us to a (more generous and not-means-tested) disability benefit. This takes care of Scott’s objection concerning what to do with those whose net “worth” to an employer is negative.
As an aside: organisations for people with disabilities, in particular the youth organisations, like the activation requirement. Their complaint is that the government does not always follow up its job guarantee in practice.
Why not a Universal Basic Income instead? Most of the weaknesses of a UBI have already been pointed out in the discussion (by rahien.din and David Friedman among others). Let me just re-state that many disabilities are really expensive. A UBI will not be sufficient to grant people with severe disabilities a good life. If voters want to provide them with above-minimum tax-financed income, the state simply cannot avoid to burden medical personnell and administrative staff with the difficult and contradictory helper/gatekeeper roles they perform in our present social security systems. It is messy, difficult, and yes there are Type I and II errors, but these problems are unavoidable if voters want to provide people with disabilities with more than what everyone else gets. (And hey this role conflict is difficult but it is not THAT difficult; after all we have been able to live with this role conflict for more than a hundred years.)
Yakimi describes the Nauru experience:
There are societies where entire populations have been unconditionally emancipated from the necessity of labor. I have seldom heard basic income advocates talk about these precedents, probably because these experiments do nothing to justify their optimism.
The Republic of Nauru has an unemployment rate of 90%. Its people do not work because their incomes are publicly subsidized, mostly by the exploitation of their island’s phosphate deposits, an industry which once provided them with the highest incomes per capita in the world. These people who once lived on a diet of coconut and fish used their sudden influx of wealth to import all the worst excesses of civilization, leaving them with the highest obesity and diabetes rates in the world and a life expectancy of 59.7 years. They’ve nearly exhausted their sources of phosphate, completely destroying the natural beauty of their island in the process, and the people are now physiologically incapable of any existence other than idleness.
We might also look to the banlieues of France, where the youth unemployment rate is over forty percent and the underclass survives, illicit economic activities aside, at the expense of the generous French welfare state. Is there any evidence at all these beneficiaries are grateful to have been freed from drudgery? If anything, their lack of economic stake only seems to aggravate their resentment against a society that is keeping them humiliatingly idle. As recent events remind us, men hate being made to feel superfluous. Nor does there any appear to be evidence that their idleness has enabled the Byrons, Churchills, Von Brauns, et al. among them to improve the world with their genius. They are quite capable of setting cars on fire, though.
There are no doubt people, like yourself, who are natural aristocrats, who are very good at finding discipline, purpose, etc. even when freed from the pressures of necessity and would benefit from a stipend. But it is solipsistic to assume that most, or even many, humans can operate functionally when made entirely independent of the disciplinary pressure of having to earn your fill. Posthuman biotrash is a big enough problem already, and basic income can only make it worse.
I certainly don’t deny that a lot of ghettos and banlieues contain some very unhappy people. But does work help?
Suppose Alex lives in a ghetto and spends 12 hours a day watching TV and eating Cheetos. Bob lives in the same ghetto, works at a gas station 8 hours a day selling people lotto tickets, then comes home and watches TV and eats Cheetos for 4 hours. Aside from economic arguments about producing value for other people, is Bob’s life more meaningful than Alex’s? Is it happier? Would you rather be Alex or Bob? Would you rather Alex exist, or Bob exist?
If you want to make the argument for work, you have to argue that it does something other than turning Alex into Bob. That it has some other effect, where Bob gets home from work and says “You know, all that lotto-ticket selling has awoken a spark of something higher in me. Instead of watching TV, I think I’m going to read Anna Karenina.” Or something. If I’m strawmanning this argument, it’s because I don’t really know how people expect it to work.
I don’t want to disagree with Yakimi. I don’t want to come out and predict “If we institute UBI, we won’t have ghettos full of Alexes”, and have you point and laugh when I’m proven wrong. I think ghettos full of Alexes is a very likely outcome. But I don’t think that’s worse than ghettos full of Bobs. I think it’s just more surprising, more unfamiliar, more of a man-bites-dog style interesting news story that will provoke concern.
Wrong Species writes:
I only have one small quibble. Amazon is relentless with their employees because they’re so competitive. Jobs guarantee programs would be anticompetitive so we probabaly wouldn’t see anything like that. In fact it would probably be the opposite where there is too little to do and a lot of it is pointless busy work, like in high school.
Yes, this is a good point. Most surveys seem to find job satisfaction is higher in the private sector than the public sector, but I could imagine the opposite being true for the most-exploited kinds of unskilled labor.
And for what it’s worth, here’s a reader who works in an Amazon warehouse commenting to say it’s really not that bad.
Naj on another way things can go wrong:
It seems to me that many people whose lives suffer due to lack of money are in significant debt and that debt payments are a large fraction of their income. If a UBI is given to everyone, how are people prevented from borrowing $100,000 against it, blowing it quickly, and then having $0 income because their UBI is all spent on interest? Solving this problem also seems full of opaque bureaucracies and Kafkaesque rituals. Unless we just ban loaning money with interest for consumptive goods at the same time(a policy I might just favor).
po8crg suggests:
Bankrupts will still be entitled to UBI. Assuming (not unreasonably) that bankruptcy laws won’t allow garnishment of UBI to pay debts, anyone with only UBI as income and more debts than assets could declare bankruptcy, surrender their assets to their creditors, and walk free from their debt.
The risk of loaning to someone with nothing but UBI would be huge, so no lender would lend.
(incidentally, the problem with this may be in the housing market, landlords will be demanding rent up-front rather than in arrears and being very aggressive about evicting people who fall behind)
Simon Sarris (author of the piece I was criticizing) writes:
The point of something like Basic Jobs is that giving people the option, but not the obligation, may result in better outcomes for some people at the margins. It’s not a panacea, it is definitely not a Utopian alternative to the largely Utopian plans of UBI because I do not think any Utopian plan as described is wise. It’s a suggestion of mere incrementalism, something to try on top of the hodge-podge of welfare that currently exists. A splint is safer than a spleen removal, as they say.
In other words, I think you are committing a mistake by comparing your Utopian vision to another Utopian vision (which I do not advocate). I do not think any Utopian vision is good or possible. You can make UBI look better by comparing it to other Utopian ideas, but this is in effect masking the deficiencies of UBI by comparing it to something else unrealistic.
I do not want to give the impression that Basic Jobs would ever accommodate everyone as UBI may intend to do. In the best case I 100% agree its positive effects would be smaller, but its implementation would also be safer. If you have a hard time imagining that, simply imagine “Maybe we should have farm subsidies, but they work more like Japan’s or Austria’s than what the US does right now.”
10240 writes:
The huge difference between UBI and public works/job guarantee (even if it’s busywork) is that you only take a public works job if you can’t get a job on the market, and don’t have any better option. With UBI, everyone would take it, and many people who can work would quit. This may make a job guarantee at least remotely feasible.
This is the same as the difference between a homeless shelter and a rent subsidy: a homeless shelter keeps one from freezing on the street, but it’s pretty shitty, so the only people who choose it are those who really don’t have any other option. It’s a built-in means test that’s much more effective than a conventional means test that can be attached to a rent subsidy.
As such, a job guarantee may even save money if it replaces unemployment benefits. Of course, implemented this way it’s a right-wing policy (aimed to minimize welfare usage and incentivize work), rather than a left-wing one. (Hungary’s right-wing government has replaced unemployment benefits with public works like this.) It works if the goal is to keep the poor from starving, rather than to give them a decent standard of living.
This is a good and important point.
I was tempted to respond to Sarris that UBI isn’t that much more utopian than BJG. After all, it can be funded by a tax such that rich people overall pay more in extra taxes than they get in UBI, middle-class people pay the same, and poor people get more in UBI than they pay in taxes. Depending on where you set the definition of “poor”, you can ensure that only the very poor/unemployed people who would go for a basic job are really getting any money from UBI. So there’s no reason to think UBI is necessarily broader-scale than BJG.
10240’s point proves me wrong. Because basic jobs are potentially unpleasant, they act as a screening mechanism so that only people who really need them will take them. That means even targeted at the same income level, they would be less universal than UBI (another commenter points out that we could produce the same effect by making people wait in line for eight hours a day to receive their daily UBI check).
I was hoping to be able to wave away the cost issue with “this is equally bad for UBI and BJG”, but I guess I can’t anymore. I am not an expert in this so I don’t have strong opinions, but I would be pretty okay with a Piketty-esque wealth tax, a Georgist land tax, or whatever experts declare to be the least stupid and distortionary tax that mostly falls on the rich. This article (possibly wrong, possibly biased) suggests that some proposals for raising taxes on the rich could produce about $250 billion/year. That’s enough to pay the poorest 10% of Americans a $10K/year basic income (ie have a basic income plus tax increases such that they break even around the 10th percentile) even before cutting any welfare programs.
In my ideal system, we would propose some sort of inherently progressive tax at some fixed percent, and say that the basic income was “however much that produces, divided by everybody”. That means that as the economy grows, the basic income increases. At the beginning, the basic income might not really be enough to live off of (especially if I got my calculations wrong). As we get more things like robot labor and productivity increases, so does the income. By the time robots are good enough to put lots of people out of work, they’re also good enough that X% of what the rich robot-owning capitalists make is quite a lot, and everybody can be comfortable.
Then various Congresspeople can debate at what point the UBI is large enough that we can eliminate various welfare programs. On the one hand, welfare programs can be sticky, so we might worry they would be overly cautious. On the other hand, many Congresspeople are Republicans, so they probably wouldn’t be.
Yaleocon on winding down UBI:
Saying “winding down basic income is easy” assumes we have an Income Czar who can just say “all right, let’s wind it down.” We wouldn’t have that. We have a democracy, and do you really want to be the guy running on “everybody gets less money each year”? It’d be like opposing social security, except even more politically impossible. Candidates—at least, the winning ones—will only ever pledge to defend or expand it. (This also probably makes UBI a fiscally unsustainable policy in the long term.)
Once those political incentives are taken into account, I think we should view UBI as an irreversible, and probably unsustainable, change to our economic system. Scott (or any other knowledgeable UBI advocate), do you stand by the assertion that UBI would be easy to end, and if so, why? (I probably prefer the status quo to UBI, for what it’s worth.)
Thegnskald on long-term effects:
The economic right likes to pretend the distribution problem is solved. The economic left likes to pretend the production problem is solved. A UBI helps alleviate the distribution issue at minimum penalty to production; relative well-being so important, the incentive to work will be as strong as ever.
A major part of the problem with modern society is that there isn’t an economic incentive to cater to the cashless, the perpetually broke, the homeless; this is a service we want performed, but the system cannot enable it, and the system limps on.
A UBI creates such an incentive. In the short-term, we will have some shortages and price increases; in the long term, we will have a new consumer base, and new industry will arrise to support it.
Inflation is one possible result, and likely unless we make it economic to build such industry. A UBI needs a corresponding decrease in regulation, in order to make it possible to produce low-cost goods for that new money to chase.
And responding to completely different comments: if a state or city wants a higher UBI, so be it. But a major advantage that the UBI offers is to incitivize people to spread out more evenly across the US, reducing population density. Likewise, a major problem with current welfare is that it disincentivizes work, by punishing those who get it (as working costs benefits, resulting in less overall available funds). I don’t think we will have a rising class of jobless vagabonds; I think instead we will have a rising class of gig-economy people, who take short-term work to get money to buy luxuries, while they mostly skate by on the UBI. This is where we are heading anyways, so this is a net improvement, by making such gig work more secure.
I see little harm and much good in a UBI, and expect it to accelerate employment relative to the current system of “You only get your benefits if you don’t work and avoid making yourself too employable”.
Gimmickless is still worried about the rent issue:
I came of age in a military town. Part of the military benefit package is a stipend, should you qualify to live off-base. I could never find a apartment or single-wide that ever cost less than that stipend. That information gets out, and gets spread. Do people with McJobs cram themselves 3-4 to a trailer to make ends meet? Yes they do.
I fail to see how landlords will not take UBI into account on what rent they charge. Will there be a price gradient that actually settles out? Possibly. Probably. But it’s almost certainly going to end up higher than what rent is now.
This definitely sounds like what would happen in the case of a captive audience in a world with no ability to increase housing stock. If you relax some of those assumptions, I fail to see why rent shouldn’t reach a balance between supply and demand the same way other necessities like food, clothing, and gas do.
Dnkndnts doubts the “universal” part of UBI:
My problem with UBI is that it’s virtually guaranteed not to actually be universal. It’s going to be “universal” for Good Citizens. We’re going to probe and test you for any sort of substance abuse and if we find anything, you’re off the program; if you have a criminal record of any sort, you’re off the program. The government is not going to sponsor your alcoholism and crack addiction!
First, I think this immediately falls into the kafkaesque nightmare disability currently has: you have to prove to the Bureaucracy that you are, in fact, a Good Citizen in the same way that you currently have to prove to the Bureaucracy that you are, in fact, Actually Disabled.
Second, the people who need UBI the most are precisely those least likely to be labeled Good Citizens. Poverty massively correlates with substance abuse and criminal behavior.
I get that I’m attacking a strawman here in some sense, but I think there’s a snowball’s chance in hell that UBI would actually be universal.
Counterexample: Social Security. As far as I know, every elderly person gets it, whether they’re a good law-abiding citizen or not.
RC Cola writes:
I’m no economist but it seems to me that this essay under-plays what I thought would have been one of the main features of a job requirement over a free-floating income. For the moment put aside complications like disability and third-party effects and just imagine the core case of a person with no job. Jobs suck, as Scott notes toward the end. But it is in everyone’s interest if everyone who is able to support themselves with jobs do so rather than resorting to compulsory confiscation of others’ money to do so. So we want obtaining such government money to be unpleasant. This isn’t to say that most people on government programs are just lazy. But people do respond to incentives, and there are probably lots of marginal cases where it would be extra hard to support oneself with a job, and an easy, frictionless transition to government support would be an easy call whereas a costly and painful one would end up causing this marginal person to choose to remain in private employment.
so what is the main obvious attractor of a government-granted income without a work obligation? I think it’s not having to have a job. So to a first order of approximation, adding a job requirement does exactly what you would want it to do. It removes the largest incentive to avail oneself of the government program, namely the removal of work obligations during work hours. We want to do this not out of a punitive motivation, or even out of a “help the recipient” motivation. We want it out of a deterrent motivation, precisely to deter availing oneself of redistributive programs that by their nature cannot work if too many people opt in. Is that not an important part of the argument here?
Thegnskald writes:
My objection [to a previous comment] comes down to this: the assumption that UBI is a solution to poverty, rather than a solution to the systemic issues inherent in a bureaucracy-administrated welfare.
This puts me at odds with Scott, who seems to favor a high UBI intended to make work obsolete for most people. I favor a low UBI which makes the bureaucracy obsolete, but isn’t intended to pull people out of poverty. My preferred solution is a debit card (or maybe just a fingerprint-enabled system to disable theft) linked to an account with daily accrual of small amounts of money; 10-18 dollars per day per adult, some possibly smaller amount for children. Do away with disability and food stamps and housing assistance and social security, keep Medicaid/Medicare. Pair this with a new classification of minimal legal rental housing that amounts to an updated-fire-code-compliant barracks (a bunk, a locker or chest, and access to a bathroom and washing facilities, probably gender-segregated; family-style housing might amount to a lockable room). Toss in density maximums on the barracks, and proximity limitations, to avoid concentrating poverty. Maybe – maybe – add in a requirement for security guards.
The goal shouldn’t be to enable a luxurious life – it should be to enable a very basic one. With daily accrual of funds, huxters and con artist won’t find viable targets, and anything more expensive than a daily meal will encourage short-term thrift and the accrual of some very basic financial knowledge.
This is a more basic lifestyle than is afforded by the current system, but removes the barriers to entry and waiting lists that plague us now. I think the “lower middle class” version of UBI is a terrible idea; it should be treated as a safety net, not a replacement for productive enterprise.
This is the incrementalist version of a UBI. Trial it, adjust as necessary.
baconbits brings up other concerns:
What does it mean to have a “basic” income? Surely housing is included, and housing prices vary wildly over different regions. Are residents of Detroit getting enough money to pay for housing in NYC or are residents of NYC getting enough money to pay for housing in Detroit, or do we have a “cost of living adjusted UBI” where some people get enough for a low end car payment and others enough for a monthly subway pass and every other conceivable difference or are we just accepting that a few (tens of) millions of people are going to not be getting a basic level of income at all while a few (tens of) millions of people are getting well over their basic level?
While we are on the subject of the disabled, well the disabled have extra health costs… are getting more in terms of UBI? Long story short as soon as UBI is introduced it will be noticed that a great many people cannot afford their health insurance payments on their UBI and there will be cries for a nationalized health insurance on top of the UBI.
What about children and married couples? How are we balancing UBI payments to families without seriously screwing up incentives there? And immigrants? And families of immigrants?
The short answer is that right after you cut the Gordian you are going to pick up the slashed pieces of rope and attempt to retie them together to hold the system in place.
The optimism that there is a simple solution to an enormous issue is overwhelming.
Ninety-Three discusses risk to private industry:
You’re being unfairly rosy towards basic income by not mentioning that it too could destroy private industry. Imagine you institute basic income and most of the McDonalds workers quit. McDonalds tries to invent robots, but can’t because robots are hard. So they raise wages in order to attract more workers. In order to pay for their increased wages, they raise prices. The market informs McDonalds that people don’t want to pay more for their fast food, and McDonalds goes bankrupt because their business model was only profitable with $8/hour wages. Higher-end restaraunts will still exist, but your basic income scheme just destroyed the entire “cheap fast food” industry.”
This seems little different from minimum wage laws. Some studies suggest that $15/hour minimum wage laws don’t seem to hurt restaurants. Others do find some negative effect, but the effect is far from catastrophic and restaurants continue to exist.
If basic income is so high that nobody will work at $15/hour ($30/hour? $45/hour?) and private industries collapse, then we must have set the basic income too high. This would be a disaster, but no more than setting the minimum wage too high would be.
David Friedman adds: “From a little googling, labor is about 20% of the cost of McDonalds franchisees. Double wages and, if they pay those wages instead of substituting more skilled labor or machinery, and prices go up by about 20%.”
From Nicholas Weininger:
Scott, you mention aristocrats as a group who seem to flourish without needing to work for a living, and cherrypick a lot of great examples, but surely you’re aware of the phenomenon of corrupt wastrel layabout aristocrats too. It’s at least perceived as common enough that today, parents who have enough money that their kids don’t ever have to work typically spend a good deal of time and effort devising constraints on the kids’ ability to access their inheritances so that they don’t become corrupt wastrel layabouts. Do you think the perception of commonness is incorrect? Are the parents worried for no reason? Note too, as other commenters have, that these parents are much more capable of instilling responsibility and work ethic in their kids than the typical parents of those who might depend on a large UBI.
This is one of many reasons why I think we should start with a very small, Alaska-fund sort of level of UBI, plus a child allowance for primary caregivers of young kids, and see how that goes for awhile before taking up the question of an increased UBI level.
Martin Freedman refers us to previous work on the subject which I should get around to reading:
Hello, long time lurker first time poster here.
This is an interesting post but it seems to miss the boat on the whole Jobs Guarantee debate and analysis that has been going on for many years. This is partly due to your post being a response to another interesting article by Simon Saris, which also, but less so, misses the boat on this debate. Still he does raise points that you sort respond to as if they were never raised e.g over disability and he emphasized no removal of those benefits.
I also read as much as I could of the 100+ comment stream and only two commentators correctly identified the real issues : ShamblerBishop and userfriendlyy.
Anyway a more substantive issue is the body of work and analysis done on the JG done by many economists over the years. You mentioned economists who had argued for a CBI or UBI where you included Milton Friedman who really argued for a Negative Income Tax which is not the same BTW (as others have noted).
However why did you not mention those economists who have argued for a JG? Where were Keynes’ On-the-spot employment, Minsky’s Employer of Last Resort, Mitchell’s Buffer Stock Employment, Mosler’s Transition Jobs and, in general, collectively named by the Modern Monetary Theory economists called the Job Guarantee?
Simon’s post using the non-standard term “Basic Jobs” – which he is entitled to do – is somewhat indicative that this is an unorthodox presentation of these ideas. He (and, for that matter, I) are unknown bloggers on this topic and, regardless, stand or fall on the quality of arguments and analysis. Whilst writing for a particular audience might have been a motivation for him, for whatever reason he omitted the critical, IMV, macroeconomic basis which is particularly important both for the JG and for a more complete evaluative comparison of the JG to BI.
If you really want to do this topic justice I humbly suggest you look to the main economist out of the MMT group who has specifically focused on this topic. (Of course, the others – mentioned above or not – have researched this aspect too, this is only my recommendation). This is Pavlina Tcherneva who has written for a range of audiences from the interested lay person to the mainstream economist academics. You could start with her Job Guarantee Faq or her team at Bard
Suffice to say all your objections have long been answered. That does not mean you agree with the arguments in those answers, of course, but a clearer discussion should start with those answers not write as if these have never been considered.
Michael Handy says:
Umm, correct me if I am wrong, but didn’t we try a Basic Jobs program back in the 19th century in England? Namely, the Workhouses, carefully calibrated to make any private sphere job heaven by comparison.
I feel that a program that literally uses the first chapters of Oliver Twist as a technical manual might not need such a comprehensive debunking, but I’m glad one exists.
On the one hand, this is unfair. The workhouse was nothing like existing basic jobs guarantees – it was a combination housing program / food program / jobs program that poor people were in many cases forbidden by law to leave. This is totally unlike proposals for a $15/hour voluntary job not linked to housing or food.
On the other, what I find most interesting about workhouses is that most sources suggest they weren’t profitable. Even offering workers the most miserable conditions and paying them no wages, they still failed to produce anything that sold well and had to be subsidized by taxpayers. This reinforces my concern that basic jobs are not going to be able to produce as much as people think.
Watchman writes:
My issue here, and this comes from someone convinced of the futility of the Keynsian approach embodied by basic jobs (the left wing are clearly bored of re-hashing the bad ideas of the 1970s and are going back to the 30s for their inspiration now…), is that basic jobs appear to be much safer for a functioning democracy than basic income. Democracy is ill served if leaders are able to use their power to effectively bribe voters: any study of the working of machine politics in US cities, or of the small electorates of English rotten boroughs, will reveal this. Basic income is a tool that in the right hands could be used to bribe voters by promising an increase in the income; in the US at least I find it easy to imagine populist figures on both sides of the political divide promising voters higher basic income. Democracy requires a certain restraint from voters and basic income would be a potential danger to this by creating a clear incentive for voters to focus on self-interest in their decision making, to a degree not currently seen (mind you, it is possible I’m just repeating arguments made when income tax was introduced…).
I agree that income tax is worth considering. The “politicians will bribe voters with their own money” thing is plausible, but how come there are still taxes? It would be pretty easy to run the federal government without making the bottom 50% of the wage distribution pay taxes at all; why don’t we? I think the answer is something like “to maintain some fiction that everyone must contribute equally”, but that makes the bribe-voters-with-their-own money strategy look pretty powerless, doesn’t it?
For that matter, free universal health care is an example of bribing voters with their own money – how come it keeps failing? So is universal college – how come no one except Bernie Sanders even pushes it? For all their flaws – and they have many – the average American voter seems remarkably bribery-resistant.
Liz writes:
Extreme example to make the point: Take a person with Down’s syndrome and give them a job (like washing dishes) which they can perform, and see how they respond to it. They’re far happier doing that as opposed to sitting at home being fed and “entertained”. However unmeaningful you might believe that work to be, it might be very meaningful to them. I’m sure there are a lot of people in the service industry (“would you like fries with that?” et al) who DO INDEED make a positive difference in people’s lives. Even a smile can do that for a frustrated, stressed out person….a smile that makes one feel they aren’t alone. A kind gesture, some simple random act of kindness of any sort can actually restore ones’ faith in humanity. So I happen to think the “fries with that?” work is meaningful. It might (depending on circumstances and how it is done, of course) be even more meaningful than far higher paid and higher skilled (on paper) labor.
Many people say they feel that they wouldn’t personally be able to handle not working very well. For example, Joyously:
The reason I have always been basic-income-skeptical is because of myself. If I had a basic income the same as my grad stipend, I could *definitely very-much* see myself mostly just playing a lot of video games. There’s a *possibility* I’d finally finish my novel. But it would be mostly video games.
And I’d be happy–but the thing is I *can* do other things that fill a slot society needs. (And I am a privileged educated person from a privileged educated background who doesn’t really *need* this assistance.) So shouldn’t I?
Yes. I think you would do great as one of the vast majority of people who would continue to work even after society had a basic income. I’m not in favor of preventing people from working. I myself would probably work even if offered a basic income. I think it’s great if people don’t have to work but want to anyway. I’m not sure how to get this point across more strongly than I already have.
Other people say that obviously everybody would quit if a Basic Income were available. Aphyer writes:
I am a programmer. I have a really good job. I quite enjoy it, I get paid well, I like my coworkers. I can listen to my favorite music over headphones while working. When someone does something stupid my coworkers and I enjoy ourselves laughing about it. I am probably somewhere north of 95th percentile job satisfaction in the country.
If you offered me enough money to support myself indefinitely while staying at home playing and designing increasingly complicated computer games and board games…well…I don’t think I would take it. Probably. But I would be very tempted.
This seems to suggest that somewhere around 90 percent of people would quit their jobs. And maybe in the Glorious Robot Future that would not be a problem. However, one thing that several of Scott’s articles on this topic seem to have missed is that we are not actually in the Glorious Robot Future yet. Yes, once you get to a position where our robot armies can do everything we want, a basic income guarantee is probably the best way to convert this into a high standard of living for many people. But we are not in that position. We are not close to that position. Right now people’s jobs are actually adding value that will be lost if they quit. And implementing a basic income guarantee now feels like it would just obviously be a disaster.
(None of this should be taken as support of a basic jobs program, which sounds even more obviously disastrous and makes me want to exhume Joseph McCarthy and turn him loose on everyone suggesting it.)
Ozy brings up that there are various ways that skilled workers can work part-time to make $10K per year (the easiest is to work a $100K job one year in ten). Since almost nobody does that, it seems unlikely that these people would really quit their job in exchange for basic income.
I’m glad Ozy showed up, because I used to think the same thing as Aphyer, and Ozy reminded me that I wasn’t taking any of the opportunities to work much less in exchange for much less money either. I wonder if this is just a universal bias, where people feel like they would definitely prefer more free time to working more, but then work more anyway.
ec429 defends the much-maligned but ever-popular position of “being angry that other people might get by without having to work”:
A lot of people have commented above on the incentive problems etc. with both UBI and UBJ, so I’ll not go into that. But I’ve noticed a bit of a thread of “why are opponents of UBI so determined that no-one ever gets a free ride?” Since this generalises to other welfare/disability/secondary distribution programs, I think my viewpoint here may be relevant. Warning: raw and emotional, rather than cool and rational. But maybe it’ll help people understand why I, at least, am so implacably opposed to redistribution. (Also it drifts a bit off-topic by the end.)
Stipulated: I’m a nerd, bookish, aspergiac. (Also, technically not fully-abled: I have a sleep disorder that prevents me working full-time.)
Between the ages of (let’s say) 8 and 18, I was bullied a lot; this was made bearable by the knowledge that in adulthood, I’d be an affluent knowledge-worker and the people bullying me were idiots who would be stuck in retail or manual labour, and that it would utterly serve the b—ers right.
And now you expect me to give up some large slice of the product of my work (when you add up income tax, national insurance*, VAT** on the goods I buy, push effects from taxes supposedly levied upon ‘business’, etc., the total tax bite is probably over 50%) to give those same b—ers welfare cheques, and then to give them more when it turns out they spent the first lot on pot and xboxes, because somehow it’s not acceptable for people who make stupid decisions to starve.
So no. If you want _my_ money to fund _your_ life, you had d-mn well better prove that you’re trying to better yourself and not just suffering the consequences of your own stupidity. Ideally, let me make that decision myself through private charity, rather than forcibly taking the decision away from me and giving it to some unaccountable bureaucrat. (If nothing else, I could hardly be _more_ Kafkaesque than the disability-scheme bureaucrats.
Good news! I hear that basic income will sap meaning and community from people’s lives. So all those bullies will be living unhappy lives without any purpose, and you’ll still have the last laugh!